{kind=link}
“Customary Deviation” is a key idea in statistics that measures/analyzes how a lot values in a dataset fluctuate from the imply. This method helps to know how constant or various the information is and the way dependable the imply worth is as a abstract statistic. Python supplies completely different strategies to find out the usual deviation, such because the “statistics.stdev()” methodology.
To find out the Python statistics customary deviation, comply with the under define:
What’s the “statistics.stdev()” Methodology in Python?
The “statistics.stdev()” methodology finds the usual deviation of a pattern of information. A excessive customary deviation signifies that the information values are far aside from one another and the common. A low customary deviation, nonetheless, implies that the information values are shut collectively and near the common.
Syntax
statistics.stdev(knowledge, xbar)
Within the above syntax:
-
- The “knowledge” parameter determines which knowledge values will probably be used (any sequence, record or iterator is allowed).
- The “xbar” parameter specifies the imply of the given knowledge.
Notice: “Customary Deviation” makes use of the identical models as the information, in contrast to variance, which makes use of squared models. Additionally, “Customary Deviation” is the sq. root of variance.
Instance 1: Figuring out the Customary Deviation
The under instance is utilized to specify the usual deviation:
import statistics
print(statistics.stdev([22, 33, 45, 17, 39, 6]))
print(statistics.stdev([–11, 2.5, –4.2, 1.2]))
Within the above code, the “statistics.stdev()” perform is utilized to compute the usual deviation of the enter pattern knowledge in each instances.
Output
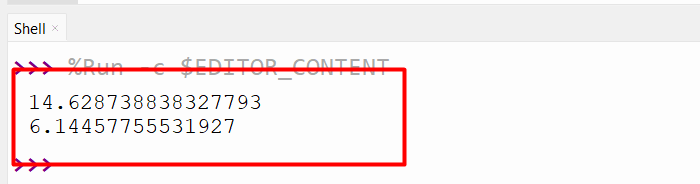
The usual deviation in every case has been calculated accordingly.
Instance 2: Figuring out the Customary Deviation Using the “xbar” Parameter
Let’s overview the under code that makes use of the mentioned parameter to compute the usual deviation:
import statistics
knowledge = (2, 5, 10, 20, 30, 44)
mean_data = statistics.imply(knowledge)
print(statistics.stdev(knowledge, xbar = mean_data))
In these code traces, the “statistics.stdev()” methodology is used to find out the usual deviation by accepting the “knowledge” and “xbar” arguments. There’s nothing particular in regards to the “xbar” parameter besides that it shops the pattern’s imply.
Output
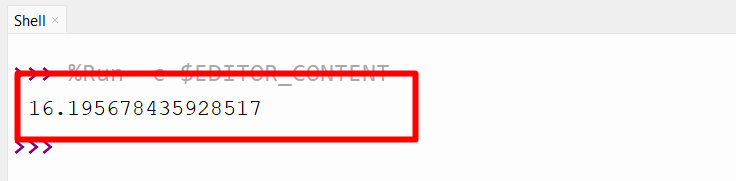
The usual deviation has been computed.
Different Approaches to Decide/Calculate the Customary Deviation
The next examples use varied different approaches to find out the usual deviation.
Instance 1: Figuring out the Customary Deviation Utilizing the “numpy.std()” Methodology
The under code snippet is used to find out the usual deviation based mostly on the “numpy.std()” methodology:
import numpy
print(numpy.std([22, 33, 54, 12, 59]))
print(numpy.std([–5, 5.5, –4.2, 4.2]))
On this code, the “numpy.std()” methodology takes the pattern knowledge as an argument and determines the corresponding customary deviation in every case.
Output
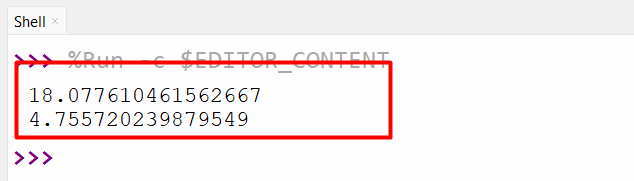
Instance 2: Figuring out the Customary Deviation Utilizing the “pandas.std()” Methodology
Right here is an instance code:
import pandas
knowledge = [2, 5, 10, 20, 30, 44]
df = pandas.DataFrame(knowledge, columns=[‘Data’])
print(df[‘Data’].std())
Within the above block of code, the “pandas.DataFrame()” perform takes the created dictionary and shops the end in “df”. The related “std()” perform of the “pandas” module then determines the corresponding customary deviation.
Output
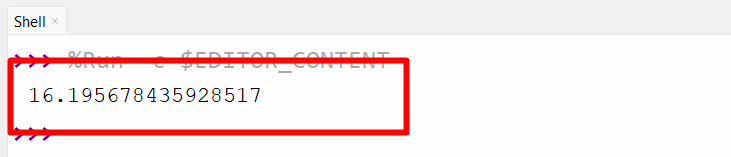
Conclusion
The “statistics.stdev()” methodology of the “statistics” module is utilized to find out/calculate the usual deviation of a pattern of information in Python. We get the usual deviation by taking the variance sq. root. Different approaches akin to “numpy.std()” and “pandas.std()” strategies may also decide the usual deviation. This weblog introduced a number of methods to find out the statistics customary deviation with related examples.