{kind=link}
Whereas working with datasets for evaluation and knowledge manipulation, builders regularly want to find out essentially the most frequent worth inside a dataset. For this objective, a strong knowledge manipulation library in Python known as “Pandas” is used. It offers essentially the most environment friendly strategies for extracting essentially the most frequent worth from a DataFrame or Sequence.
On this put up, we are going to display the strategies for extracting essentially the most frequent worth utilizing Pandas.
Easy methods to Get the Most Frequent Worth in Pandas?
For getting essentially the most frequent worth in pandas, use the next strategies:
Methodology 1: Get the Most Frequent Worth Utilizing “mod()” Methodology
To search out the values which are used essentially the most regularly in knowledge frames utilizing Pandas, make the most of the panda’s collection “mod()” methodology. It returns a collection containing essentially the most frequent values within the authentic collection, as there may be a number of values with the identical highest frequency.
Instance
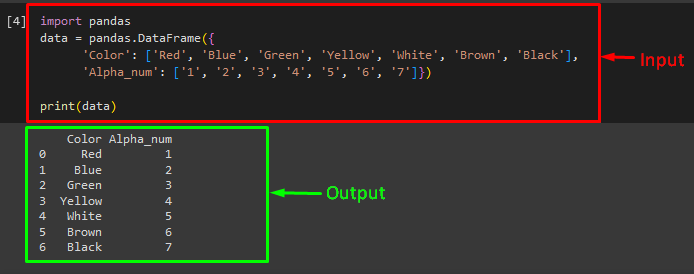
On this instance, first, we are going to create an information body utilizing the “DataFrame()” methodology of the “pandas” library after which print it on the console:
knowledge = pandas.DataFrame({
‘Shade’: [‘Red’, ‘Blue’, ‘Green’, ‘Yellow’, ‘White’, ‘Brown’, ‘Black’],
‘Alpha_num’: [‘1’, ‘2’, ‘3’, ‘4’, ‘5’, ‘6’, ‘7’]})
print(knowledge)
Output
Now, name the “mod()” methodology on the array “Alpha_num” of the info body to get the repetitive values in an array:
print(knowledge[‘Alpha_num’].mode())
The below-given output reveals that the “1” and “2” are essentially the most frequent values within the array “Alpha_num”: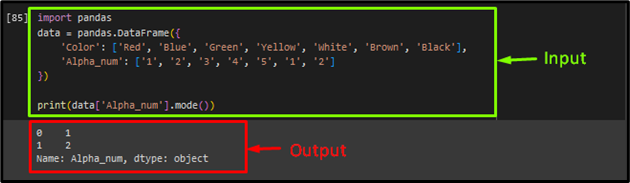
Methodology 2: Get Most Frequent Worth Utilizing “value_counts()” Methodology With “idxmax()” Methodology
Use the “value_counts()” methodology adopted by “idxmax()” methodology. The “value_counts()” methodology counts the occurrences of every distinctive worth, and the “idxmax()” methodology returns the worth with the best depend.
Instance
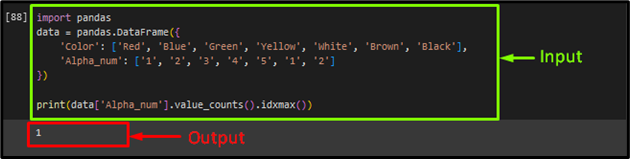
Right here, we are going to name the “value_counts()” methodology with the “idxmax()” methodology on the array “Alpha_num” of the info body to get the repetitive values within the array. The “value_counts()” methodology will first get the frequency depend of every distinctive worth after which, retrieve essentially the most frequent worth utilizing the “idxmax()” methodology:
print(knowledge[‘Alpha_num’].value_counts().idxmax())
The given output signifies that the “1” is essentially the most frequent worth on the array “Alpha_num”:
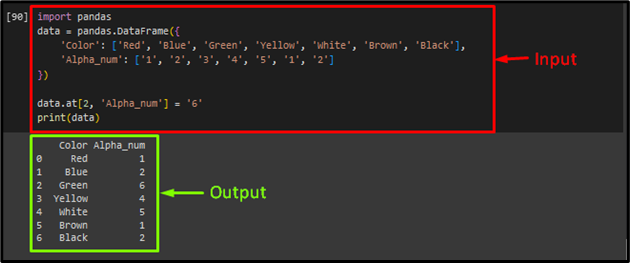
You too can replace the values at any index of the array in an information body with the assistance of the “at” attribute:
print(knowledge)
As you may see that the worth of “Inexperienced” at index “2” has been efficiently up to date from “3” to “6”:
That was all concerning the pandas getting essentially the most frequent worth in Python.
Conclusion
To get essentially the most frequent worth in pandas, use the panda collection “mod()” methodology or the “value_counts()” methodology adopted by the “idxmax()” methodology. The primary strategy panda collection “mod()” methodology is beneficial for getting the collection of most frequent values. On this put up, we demonstrated the strategies for extracting essentially the most frequent worth utilizing Pandas.