
{kind=link}
Discussions at chip design conferences hardly ever get heated. However a 12 months in the past on the Worldwide Symposium on Bodily Design (ISPD), issues bought out of hand. It was described by observers as a “trainwreck” and an “ambush.” The crux of the conflict was whether or not Google’s AI resolution to certainly one of chip design’s thornier issues was actually higher than these of people or state-of-the-art algorithms. It pitted established male digital design automation (EDA) specialists in opposition to two younger feminine Google pc scientists, and the underlying argument had already led to the firing of 1 Google researcher.
This 12 months at that very same convention, a frontrunner within the subject, IEEE Fellow Andrew Kahng, hoped to place an finish to the acrimony as soon as and for all. He and colleagues on the College of California, San Diego, delivered what he referred to as “an open and clear evaluation” of Google’s reinforcement studying strategy. Utilizing Google’s open-source model of its course of, referred to as Circuit Coaching, and reverse-engineering some components that weren’t clear sufficient for Kahng’s workforce, they set reinforcement studying in opposition to a human designer, industrial software program, and state-of-the-art educational algorithms. Kahng declined to talk with IEEE Spectrum for this text, however he spoke to engineers final week at ISPD, which was held just about.
Typically, Circuit Coaching was not the winner, but it surely was aggressive. That’s particularly notable on condition that the experiments didn’t enable Circuit Coaching to make use of its signature capability—to enhance its efficiency by studying from different chip designs.
“Our objective has been readability of understanding that can enable the neighborhood to maneuver on,” he instructed engineers. Solely time will inform whether or not it labored.
The Hows and the Whens
The issue in query known as placement. Principally, it’s the strategy of figuring out the place chunks of logic or reminiscence must be positioned on a chip with the intention to maximize the chip’s working frequency whereas minimizing its energy consumption and the world it takes up. Discovering an optimum resolution to this puzzle is among the many most troublesome issues round, with extra attainable permutations than the sport Go.
However Go was in the end defeated by a kind of AI referred to as deep reinforcement studying, and that’s simply what former Google Mind researchers Azalia Mirhoseini and Anna Goldie utilized to the position downside. The scheme, then referred to as Morpheus, treats inserting giant items of circuitry, referred to as macros, as a sport, studying to seek out an optimum resolution. (The areas of macros have an outsize impression on the chip’s traits. In Circuit Coaching and Morpheus, a separate algorithm fills within the gaps with the smaller components, referred to as normal cells. Different strategies use the identical course of for each macros and normal cells.)
Briefly, that is the way it works: The chip’s design file begins as what’s referred to as a netlist—which macros and cells are related to which others based on what constraints. The usual cells are then collected into clusters to assist pace up the coaching course of. Circuit Coaching then begins inserting the macros on the chip “canvas” one by one. When the final one is down, a separate algorithm fills within the gaps with the usual cells, and the system spits out a fast analysis of the try, encompassing the size of the wiring (longer is worse), how densely packed it’s (extra dense is worse), and the way congested the wiring is (you guessed it, worse). Known as proxy price, this acts just like the rating would in a reinforcement-learning system that was determining the best way to play a online game. The rating is used as suggestions to regulate the neural community, and it tries once more. Wash, rinse, repeat. When the system has lastly discovered its process, industrial software program does a full analysis of the whole placement, producing the type of metrics that chip designers care about, akin to space, energy consumption, and constraints on frequency.
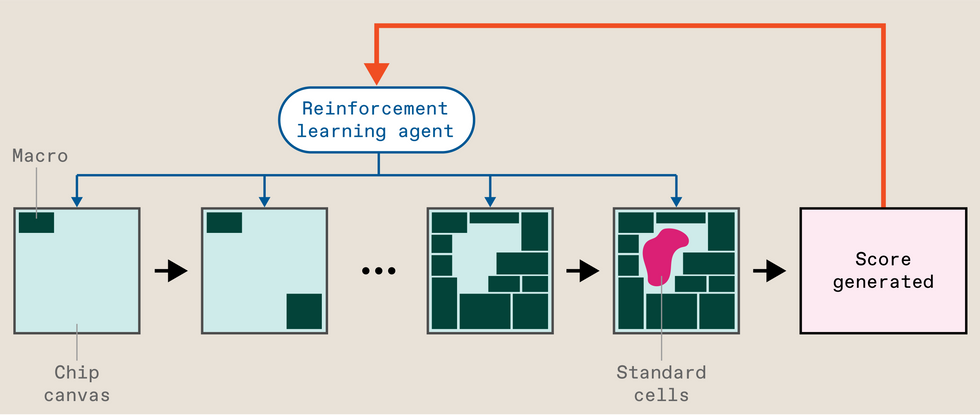 Google’s reinforcement studying system treats inserting giant circuit blocks referred to as macros as a sport. The agent locations one block at a time on the chip canvas. Then a separate algorithm fills in smaller components referred to as normal cells. The position is scored based on a number of metrics, and that rating is used as suggestions to enhance the agent.IEEE Spectrum
Google’s reinforcement studying system treats inserting giant circuit blocks referred to as macros as a sport. The agent locations one block at a time on the chip canvas. Then a separate algorithm fills in smaller components referred to as normal cells. The position is scored based on a number of metrics, and that rating is used as suggestions to enhance the agent.IEEE Spectrum
Mirhoseini and Goldie revealed the outcomes and technique of Morpheus in Nature in June 2021, following a seven-month assessment course of. (Kahng was reviewer No. 3.) And the approach was used to design multiple technology of Google’s TPU AI accelerator chips. (So sure, knowledge you used immediately might have been processed by an AI operating on a chip partly designed by an AI. However that’s more and more the case as EDA distributors akin to Cadence and Synopsys go all in on AI-assisted chip design.) In January 2022, they launched an open-source model, Circuit Coaching, on GitHub. However Kahng and others declare that even this model was not full sufficient to breed the analysis.
In response to the Nature publication, a separate group of engineers, largely inside Google, started analysis geared toward what they believed to be a greater method of evaluating reinforcement studying to established algorithms. However this was no pleasant rivalry. In accordance with press experiences, its chief Satrajit Chatterjee, repeatedly undermined Mirhoseini and Goldie personally and was fired for it in 2022.
Whereas Chatterjee was nonetheless at Google, his workforce produced a paper titled “Stronger Baselines,” important of the analysis revealed in Nature. He sought to have it offered at a convention, however after assessment by an impartial decision committee, Google refused. After his termination, an early model of the paper was leaked by way of an nameless Twitter account simply forward of ISPD in 2022, resulting in the general public confrontation.
Benchmarks, Baselines, and Reproducibility
When IEEE Spectrum spoke with EDA specialists following ISPD 2022, detractors had three interrelated considerations—benchmarks, baselines, and reproducibility.
Benchmarks are overtly out there blocks of circuitry that researchers check their new algorithms on. The benchmarks when Google started its work have been already about 20 years previous, and their relevance to fashionable chips is debated. College of Calgary professor Laleh Behjat compares it to planning a contemporary metropolis versus planning a Seventeenth-century one. The infrastructure wanted for every is completely different, she says. Nevertheless, others level out that there isn’t any method for the analysis neighborhood to progress with out everybody testing on the identical set of benchmarks.
As an alternative of the benchmarks out there on the time, the Nature paper centered on doing the position for Google’s TPU, a posh and cutting-edge chip whose design will not be out there to researchers exterior of Google. The leaked “Stronger Baselines” work positioned TPU blocks but in addition used the previous benchmarks. Whereas Kahng’s new work additionally did placements for the previous benchmarks, the principle focus centered on three more-modern designs, two of that are newly out there, together with a multicore RISC-V processor.
Baselines are the state-of-the artwork algorithms your new system competes in opposition to. Nature in contrast a human professional utilizing a industrial device to reinforcement studying and to the main educational algorithm of the time, RePlAce. Stronger Baselines contended that the Nature work didn’t correctly execute RePlAce and that one other algorithm, simulated annealing, wanted to be in contrast as nicely. (To be honest, simulated annealing outcomes appeared within the addendum to the Nature paper.)
However it’s the reproducibility bit that Kahng was actually centered on. He claims that Circuit Coaching, because it was posted to GitHub, fell in need of permitting an impartial group to totally reproduce the process. In order that they took it upon themselves to reverse engineer what they noticed as lacking parts and parameters.
Importantly, Kahng’s group publicly documented the progress, code, knowledge units, and process for example of how such work can improve reproducibility. In a primary, they even managed to influence EDA software program corporations Cadence and Synopsys to permit the publication of the high-level scripts used within the experiments. “This was an absolute watershed second for our subject,” stated Kahng.
The UCSD effort, which is referred to easily as MacroPlacement, was not meant to be a one-to-one redo of both the Nature paper or the leaked Stronger Baselines work. In addition to utilizing fashionable public benchmarks unavailable in 2020 and 2021, MacroPlacement compares Circuit Coaching (although not the latest model) to a industrial device, Cadence’s Innovus concurrent macro placer (CMP), and to a technique developed at Nvidia referred to as AutoDMP that’s so new it was solely publicly launched at ISPD 2023 minutes earlier than Kahng spoke.
Reinforcement Studying vs. All people
Kahng’s paper experiences outcomes on the three fashionable benchmark designs carried out utilizing two applied sciences—NanGate45, which is open supply, and GF12, which is a industrial GlobalFoundries FinFET course of. (The TPU outcomes reported in Nature used much more superior course of applied sciences.) Kahng’s workforce measured the identical six metrics Mirhoseini and Goldie did of their Nature paper: space, routed wire size, energy, two timing metrics, and the beforehand talked about proxy price. (Proxy price will not be an precise metric utilized in manufacturing, but it surely was included to reflect the Nature paper.) The outcomes have been blended.
Because it did within the authentic Nature paper, reinforcement studying beat RePlAce on most metrics for which there was a head-to-head comparability. (RePlAce didn’t produce a solution for the most important of the three designs.) Versus simulated annealing, Circuit Coaching gained greater than it misplaced on the manufacturing metrics.
For these experiments, the large winners have been the most recent entrants CMP and AutoDMP, which delivered the most effective metrics in additional circumstances than every other technique.
Within the assessments meant to match Stronger Baselines, utilizing older benchmarks, each RePlAce and simulated annealing virtually at all times beat reinforcement studying. However these outcomes report just one manufacturing metric, wire size, so that they don’t current a whole image, argue Mirhoseini and Goldie.
A Lack of Studying
Understandably, Mirhoseini and Goldie have their very own criticisms of the MacroPlacement work, however maybe crucial is that it didn’t use neural networks that had been pretrained on different chip designs, robbing their technique of its fundamental benefit. Circuit Coaching “not like any of the opposite strategies offered, can be taught from expertise, producing higher placements extra shortly with each downside it sees,” they wrote in an e mail.
However within the MacroPlacement experiments every Circuit Coaching outcome got here from a neural community that had by no means seen a design earlier than. “That is analogous to resetting AlphaGo earlier than every match…after which forcing it to discover ways to play Go from scratch each time it confronted a brand new opponent!”
The outcomes from the Nature paper bear this out, exhibiting that the extra blocks of TPU circuitry the system discovered from, the higher it positioned macros for a block of circuitry it had not but seen. It additionally confirmed {that a} reinforcement-learning system that had been pretrained may produce a placement in 6 hours of the identical high quality as an untrained one after 40 hours.
New Controversy?
Kahng’s ISPD presentation emphasised a selected discrepancy between the strategies described in Nature and people of the open-source model, Circuit Coaching. Recall that, as a preprocessing step, the reinforcement-learning technique gathers up the usual cells into clusters. In Circuit Coaching, that step is enabled by industrial EDA software program that outputs the netlist—what cells and macros are related to one another—and an preliminary placement of the elements.
In accordance with Kahng, the existence of an preliminary placement within the Nature work was unknown to him whilst a reviewer of the paper. In accordance with Goldie, producing the preliminary placement, referred to as bodily synthesis, is normal business observe as a result of it guides the creation of the netlist, the enter for macro placers. All placement strategies in each Nature and MacroPlacement got the identical enter netlists.
Does the preliminary placement someway give reinforcement studying a bonus? Sure, based on Kahng. However it’s not clear from the experiments to date to what extent and even why. His group did experiments that fed three completely different unattainable preliminary placements into Circuit Coaching and in contrast them to an actual placement. Routed wire lengths for the unattainable variations have been between 7 and 10 % worse.
Mirhoseini and Goldie counter that the preliminary placement info is used just for clustering normal cells, which reinforcement studying doesn’t place. The macro-placing reinforcement studying portion has no information of the preliminary placement, they are saying. What’s extra, offering unattainable preliminary placements could also be like taking a sledgehammer to the usual cell-clustering step and due to this fact giving the reinforcement-learning system a false reward sign. “Kahng has launched a drawback, not eliminated a bonus,” they write.
Kahng means that extra rigorously designed experiments are forthcoming.
Shifting On
This dispute has definitely had penalties, most of them damaging. Chatterjee is locked in a wrongful-termination lawsuit with Google. Kahng and his workforce have spent an excessive amount of effort and time reconstructing work achieved—maybe a number of instances—years in the past. After spending years heading off criticism from unpublished and unrefereed analysis, Goldie and Mirhoseini, whose goal was to assist enhance chip design, have left a subject of engineering that has traditionally struggled to draw feminine expertise. Since August 2022 they’ve been at Anthropic engaged on reinforcement studying for giant language fashions.
If there’s a shiny facet, it’s that Kahng’s effort presents a mannequin for open and reproducible analysis and added to the shop of overtly out there instruments to push this a part of chip design ahead. That stated, Mirhoseini and Goldie’s group at Google had already made an open-source model of their analysis, which isn’t frequent for business analysis and required some nontrivial engineering work.
Regardless of all of the drama, the usage of machine studying typically, and reinforcement studying particularly, in chip design, has solely unfold. Multiple group was capable of construct on Morpheus even earlier than it was made open supply. And machine studying is helping in ever-growing features of economic EDA instruments, akin to these from Synopsys and Cadence.
However all that good may have occurred with out the unpleasantness.
This put up was corrected on 4 April. CMP was incorrectly characterised as being a brand new device.
To Probe Additional:
The MacroPlacement mission is extensively documented on GitHub.
Google’s Circuit Coaching entry on GitHub is right here.
Andrew Kahng paperwork his involvement with the Nature paper right here. Nature revealed the peer-review file in 2022.
Mirhoseini and Goldie’s response to MacroPlacement will be discovered right here.
From Your Web site Articles
Associated Articles Across the Net